Adaptive Granularity Importance Sampling for Policy Optimization
A speech-oriented perspective on moving beyond token-level and sequence-level importance weighting
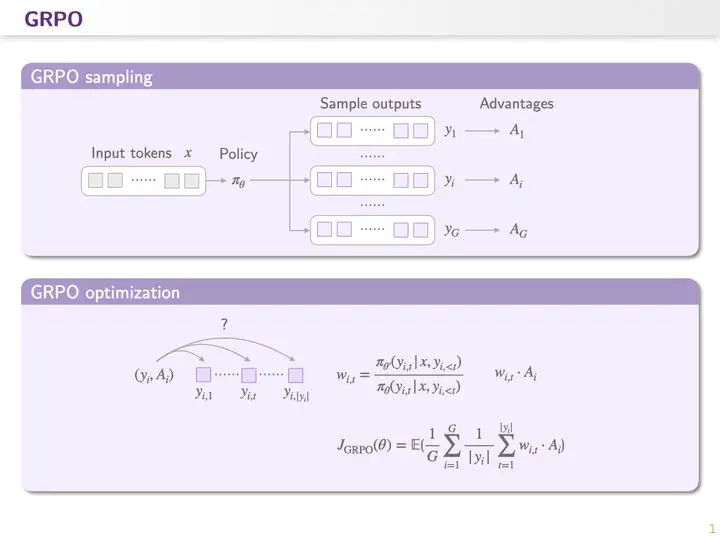
Let us first revisit the optimization step in standard GRPO. For each sampled completion, we compute an advantage and distribute that advantage across tokens during optimization through importance weights.
In GRPO, the importance term measures how much the current policy differs from the previous policy in the token distribution at a particular generation step. A larger importance score indicates that the updated policy changes its behavior more substantially at that token, and that token is therefore treated as a more important target for optimization.

However, this procedure exposes a theoretical issue in GRPO. Importance sampling is justified when one estimates an expectation over multiple samples drawn from the behavior distribution in order to correct distribution mismatch. In GRPO, by contrast, each token position contains only a single sample. As a result, the token-level importance weight does not perform proper distribution correction; instead, it introduces high-variance noise. This noise accumulates along the sequence length and can be further amplified by clipping, eventually causing irreversible model collapse.
In other words, except for the first token, the remaining tokens are not independent and identically distributed in the strict theoretical sense.
This is precisely the motivation behind Qwen’s GSPO. Their key observation is that although tokens are not i.i.d., the entire sequence can still be treated as the unit of sampling. Therefore, if the importance score is computed at the sequence level rather than the token level, the mismatch-correction argument becomes much more defensible.
Methodologically, GSPO is straightforward. It computes a single importance score for the entire sequence and applies that same score to all tokens. The benefit is that gradients across tokens are weighted uniformly. This fundamentally removes the instability introduced by unequal token-wise weighting in GRPO.

Starting from GSPO, a broader discussion has emerged around token-level versus sequence-level optimization and their intermediate alternatives.

A concise summary of the tradeoff is as follows:
- Token-level methods: computing an importance score for every token violates the i.i.d. assumption required for rigorous importance correction. In return, these methods offer fine-grained control.
- Sequence-level methods: sequence-wise importance scores are insensitive to output length, which can become problematic when reward depends explicitly or implicitly on sequence length. They also discard credit-assignment information, making it difficult for the model to focus on the parts of the output that matter most for optimization.

This motivates approaches that lie between token-level and sequence-level weighting, such as paragraph-based segmentation or entropy-based segmentation. These methods are primarily designed for text. For speech, however, the underlying assumptions are different.

- We assume token dependencies are relatively weak in text.
- Entropy patterns are highly structured. Studies of token entropy in LLM reasoning (Wang et al., 2025; Deng et al., 2025) suggest that more than 50% of text tokens have extremely low entropy ($H_t < 0.01$), whereas only about 20% of tokens are high-entropy “forking tokens.” This bimodal pattern implies that most text tokens are highly predictable given the prefix, so their importance ratio $w_t = \pi_\theta(y_t \mid \cdot) / \pi_{\theta_{\text{old}}}(y_t \mid \cdot)$ stays close to 1 and contributes little meaningful gradient signal. Only a relatively small number of tokens at semantic decision points carry most of the truly useful policy update signal.
- BPE tokenization introduces partial independence. Byte-Pair Encoding decomposes text into subword units, and word boundaries themselves act as natural break points. The conditional distribution at the beginning of a new word, $\pi(\cdot \mid x, y_{<t})$, differs substantially from the conditional distribution in the middle of a word, where the prefix strongly constrains the continuation. This creates alternating regions of high and low dependence.
- Semantic structure provides natural segmentation cues. Reasoning traces often have explicit step boundaries such as line breaks, “Step 1:”, or “Therefore,”. Code has statement and block boundaries. Natural language has sentence boundaries. These are all human-interpretable segmentation points with semantic meaning.
- We assume token dependencies are substantially stronger in speech.
- Physical continuity imposes hard constraints. Speech is generated by a continuous physical system. Fundamental frequency ($F_0$), formant trajectories, and amplitude envelopes evolve smoothly over time. When speech is tokenized at 50 Hz, as in EnCodec-like settings, adjacent tokens correspond to roughly 20 ms windows and are necessarily similar to one another. Their variation is dominated by continuity priors in the underlying signal.
- Prosodic structure spans many tokens. A syllable at 50 Hz often occupies 5-15 tokens, while a prosodic phrase can span 50-200 tokens. Pitch contour, speaking rate, and stress are all supra-segmental phenomena: they are properties of a group of tokens rather than any single token. The importance of a speech token therefore cannot be meaningfully separated from its prosodic context.
- Codec architectures enforce local dependence. Neural codecs such as EnCodec and SoundStream employ convolutional encoders whose receptive fields often cover around 320 ms. This means each token representation already incorporates information from roughly 16 neighboring frames. Residual vector quantization (RVQ) further entangles information across time. The ACM Multimedia 2025 work on compressed-to-fine language modeling explicitly shows that speech-token prediction is dominated by local context, i.e. short-range dependence.
- Mutual-information analyses support this entanglement view. Studies of SpeechTokenizer and related codecs show that pitch, speaker identity, and linguistic content are entangled across RVQ levels. The first RVQ layer tends to capture semantic content, while later layers carry prosody and timbre. Even within a given layer, however, adjacent tokens still share substantial mutual information due to signal continuity.

Overall, our objective is to group tokens according to temporal adjacency and domain-specific dependency structure. Tokens within a group should remain contiguous in time. The grouping should reflect the physical and semantic structure of the signal, rather than the internal state of the model.
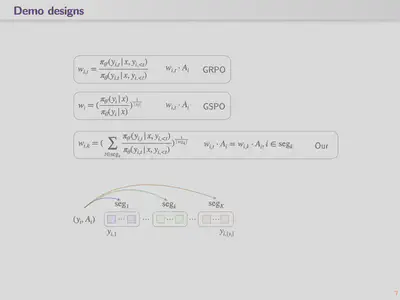
Below are the initial approaches we are currently exploring.
MASPO-Fixed: fixed-window segmentation
Implementation. Split each generated completion into $\lceil T / W \rceil$ non-overlapping segments using a fixed window size $W$. All tokens within a segment share the same importance-sampling ratio.
Rationale. Speech codec tokens (e.g. XCodec2 at 50 Hz) naturally operate across multiple physical time scales. $W = 5$ corresponds to about 100 ms, roughly the duration of a phoneme. $W = 15$ corresponds to about 300 ms, close to a syllable. $W = 50$ corresponds to roughly 1 second, which is closer to a prosodic phrase. By varying $W$, the granularity of importance weighting can be aligned with different acoustic units.
Theoretical intuition. The central argument is that tokens inside a segment are highly correlated and should not be treated as independent samples. Importance-sampling theory requires independent samples from the proposal distribution for proper correction. Within a single phoneme, however, speech codec tokens are nearly deterministic: formant trajectories are continuous and token log-probabilities are often very high, with entropy close to zero. Applying token-level importance sampling to such highly correlated tokens is not theoretically well-founded and unnecessarily increases variance. Fixed-window segmentation is the simplest de-correlation strategy: it assumes strong dependence within a window and comparatively weaker dependence across windows.
Advantages. The method is extremely simple to implement, essentially one line of code such as torch.arange(T) // W. It introduces no extra computation, has only one hyperparameter ($W$), and provides a clean interpolation between GRPO ($W = 1$) and GSPO ($W = T$), making it convenient for ablation across the full granularity spectrum.
Limitations. A fixed window cannot adapt to actual acoustic boundaries. A phoneme may span four tokens in one case and eight tokens in another. As a consequence, fixed segmentation may cut through a phoneme or merge different phonemes into the same segment.
MASPO-LogProb: adaptive segmentation via log-probability drops
Rationale. This method is based on a simple physical intuition: the log-probability under the old policy reflects token predictability. Within a phoneme, subsequent tokens are largely determined by the preceding formant trajectory, so log-probabilities are high and stable. At phoneme or syllable boundaries, the model must transition into a new acoustic unit, uncertainty rises, and the log-probability drops noticeably. A log-probability drop can therefore serve as a natural acoustic-boundary detector.
Theoretical intuition. This method is related in spirit to ESPO (Entropy-Sorted Policy Optimization), but the objective is different. ESPO emphasizes that token entropy determines how much each token contributes to reinforcement learning, with high-entropy tokens functioning as branching points and low-entropy tokens contributing little. MASPO-LogProb takes a complementary view: rather than grouping tokens by entropy value, which breaks temporal continuity, it uses the temporal variation of entropy or log-probability to identify contiguous acoustic boundaries. In speech, continuity is essential because adjacent tokens represent the same evolving physical waveform.
A second advantage is that the method requires zero additional computation. The log-probabilities under $\pi_{\theta_{\text{old}}}$ are already computed during rollout for the GRPO importance ratio, so boundary detection does not require any extra forward pass.
Advantages. The segmentation is adaptive and data-driven, can align automatically with acoustic boundaries, and can be made sample-specific by using each sample’s own $\mu$ and $\sigma$, which improves robustness across speaking styles and speaking rates.
Limitations. The threshold $\tau$ remains a hyperparameter. If $\tau$ is too large, the segments become overly coarse and the method approaches GSPO. If $\tau$ is too small, the segments become overly fine and the method collapses back toward GRPO. Moreover, a log-probability drop is only an imperfect proxy for an acoustic boundary: some true boundaries may still be easy for the model to predict, while some non-boundary positions may trigger confusion due to rare pronunciations.
MASPO-TokenVal: segmentation via codec token-ID jumps
Rationale. This method exploits the geometric structure of the VQ codebook. In XCodec2, the codebook embeddings learned through vector quantization tend to map acoustically similar signals to nearby codebook entries. This locality is an indirect by-product of VQ training, which behaves somewhat like a K-means-style clustering procedure. Consequently:
- Within a phoneme: acoustic attributes such as $F_0$, formants, and amplitude evolve smoothly, so consecutive frames tend to map to nearby codebook entries and token-ID differences remain small.
- At acoustic transitions: new phoneme onsets, voicing switches, or pitch resets can cause abrupt changes in the acoustic representation, leading to larger jumps in codebook index.
Hence, $|id_t - id_{t-1}|$ exceeding a threshold can be used as a rough proxy for an acoustic boundary.
Theoretical intuition. The plausibility of this method comes from two perspectives. First, from an information-theoretic perspective, if codebook ordering perfectly preserved acoustic distance, then token-ID differences would be an exact proxy for acoustic change. In practice, standard VQ training does not guarantee this property, but some degree of locality is often observed empirically, especially for single-codebook codecs such as XCodec2. Second, from a practical perspective, this method is entirely independent of model log-probabilities and relies only on the token sequence itself. It therefore captures data-side acoustic structure rather than model-side uncertainty, making it complementary to MASPO-LogProb.
Advantages. The method is extremely lightweight, requiring only subtraction and comparison, and does not depend on any model outputs. Conceptually, it is also the most direct and intuitive formulation.
Limitations. The main concern is that the index order of a VQ codebook is not guaranteed to be acoustically smooth. In standard VQ-VAE-style training, including XCodec2, codebook entries are updated by K-means-like or EMA-based procedures, and the assignment of discrete indices is effectively arbitrary. Two neighboring indices may correspond to very different acoustic patterns. Therefore, token-ID difference is not a theoretically reliable acoustic-distance proxy and must be calibrated empirically, for example by inspecting the histogram of adjacent ID differences. If index locality is weak, this method may degenerate into an almost random segmentation rule.
Questions or Feedback?
If you'd like to discuss ideas, implementation details, or follow-up questions from this post, feel free to open a GitHub issue or connect with me on LinkedIn.
Chang ZENG 曾畅 曾 暢 (ソウ チョウ)
Senior Research Scientist
Senior Research Scientist in generative audio, voice LLMs, and multimodal AI, with experience from research to production.