Adaptive Granularity Importance Sampling for Policy Optimization(中文)
面向语音场景的自适应粒度重要性采样笔记
English version | Slides (PDF)
首先我们看一看标准 GRPO 的 optimization 部分是怎么计算的:对于每一个 sample,我们有它的 advantage,在 optimization 的过程中,我们通过 importance score 把 advantage 分配给每一个 token.
GRPO 中的 importance 计算方式是“相比之前的 policy,当前 policy 在生成一个 token 时候 logits 分布的差异”。Importance score 越高,说明正在更新的 policy 在生成这个 token 的时候最显著,也是着重需要更新的地方。
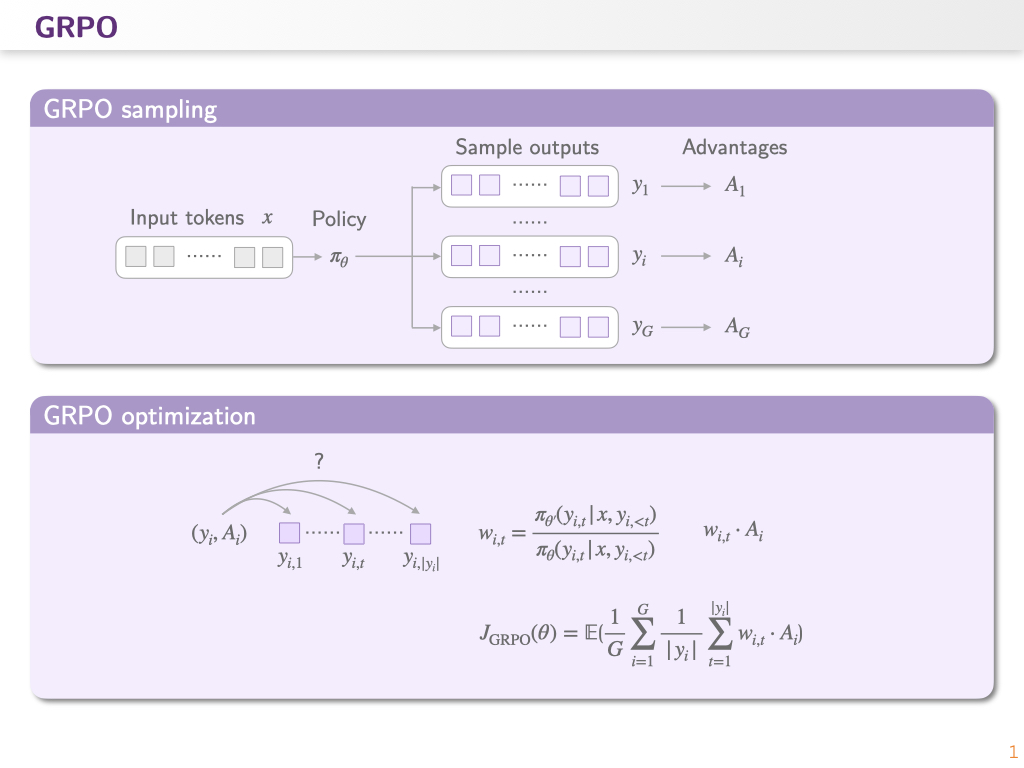
但是 GRPO 的 optimization 中有一个理论上的问题:importance sampling 的理论要求是在 behavior distribution 上采多个样本求期望来纠正分布偏差。但在 GRPO 中,每个 token position 上只有一个样本,所以这个 token-level importance weight 无法起到分布校正的作用,反而引入了高方差噪声。这些噪声会随着 sequence 长度累积,并被 clipping 机制进一步放大,最终导致不可逆的 model collapse.
换句话说理论上除了第一个 token,剩下的 tokens 都不是独立同分布的。
这就是 Qwen 的 GSPO 的 motivation,他们的方法就是,虽然 tokens 不是独立同分布的,但是整个 sequence 理论上是独立同分布的,所以说如果我们算 importance score 的时候是针对一整个 sequence 来算的话,那么就可以解决这个问题。
GSPO 方法上其实很简单,对于一整个 sequence 我们只计算一个 importance score,之后所有的 token 都用这个 importance score。这个方法带来的好处是 token 之间的 gradient 被均匀加权。这从根本上消除了 GRPO 中 token-level 不等权重带来的不稳定性。

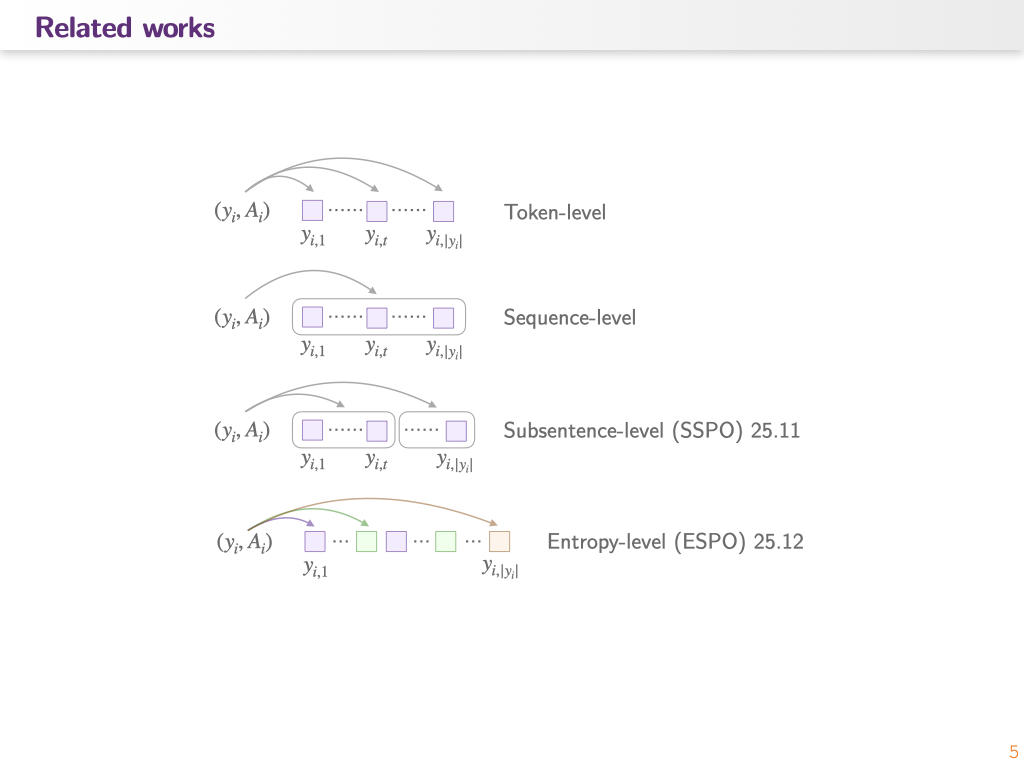
从 GSPO 开始,有一系列 token-level 和 sequence-level optimization 的讨论(related works)。

总结一下这些方法普遍遇到的问题:
- Token-level 的问题:理论上针对每一个 token 计算 importance score 时,不满足独立同分布的条件,因此逐 token 的 importance score 无法进行严格有效的分布校正。但它提供了细粒度控制。
- Sequence level 的问题:一是这样计算出来的 importance score 对长度无感,当 reward 和 output sequence 的长度有显性或隐性的关系时会产生问题;二是丢失了 credit assign 的信息,通过 sequence 的方法让模型无法专注于提升重点要优化的部分,会让优化变得很低效率。

所以说后续有了介于 token-level 和 sequence-level 中间的方法:按照段落分割和按照 entropy 分割。这些方法都是针对 text 数据的,对于 speech 数据我们有着不同的假设:
- 我们认为文本之间的 token 依赖较弱:
- 熵的变化高度结构化。 关于 LLM 推理过程中 token 熵模式的研究(Wang et al., 2025;Deng et al., 2025)表明,超过 50% 的文本 token 具有极低熵($H_t < 0.01$),而只有约 20% 的 token(“forking tokens”,分叉 token)具有高熵。这种双峰分布意味着:大多数文本 token 在给定前缀时都高度可预测,其重要性比 $w_t = \pi_\theta(y_t \mid \cdot) / \pi_{\theta_{\text{old}}}(y_t \mid \cdot)$ 会非常接近 1,因此对梯度信号贡献很小。只有少数位于语义决策点上的高熵 token(例如 “however”“since” 或逻辑分支位置)承载了大部分真正有意义的策略更新。
- BPE 分词带来部分独立性。 Byte-Pair Encoding 将文本切分为子词单元,而词边界本身就是自然的独立点。新词起始位置处的条件分布 $\pi(\cdot \mid x, y_{<t})$,与词中间位置的条件分布显著不同,因为在词中间,已有前缀会强约束后续内容。这就形成了高依赖与低依赖交替出现的自然“片段”。
- 语义结构提供了分段线索。 推理轨迹通常具有显式步骤边界(换行、“Step 1:”、“Therefore,” 等),代码具有语句/代码块边界,自然语言具有句子边界。这些都是人类自然使用、且具有语义意义的分段点。
- 同时我们认为语音 token 之间的依赖较强:
- 物理连续性约束。 语音由连续的物理系统(声道)产生。基频(F0)、共振峰轨迹和振幅包络都是平滑变化的。当语音以 50 Hz 的频率被 token 化(例如 EnCodec)时,相邻 token 对应大约 20ms 的音频窗,它们在物理上必然彼此相似。token 之间的变化主要受底层连续信号的平滑先验所支配。
- 韵律结构跨越大量 token。 一个音节在 50 Hz 下通常占据 5-15 个 token;一个韵律短语则可能跨越 50-200 个 token。音高轮廓、语速和重音本质上都是超音段特征,它们是一组 token 的属性,而不是单个 token 的属性。单个语音 token 的重要性无法脱离其韵律上下文而被有意义地分离。
- Codec 架构强制局部依赖。 EnCodec 和 SoundStream 这类神经 codec 使用卷积编码器,其感受野通常覆盖约 320ms,这意味着每个 token 的表示本身就已经包含了约 16 个相邻帧的信息。残差向量量化(RVQ)进一步在时间维度上缠结了信息。ACM Multimedia 2025 的 compressed-to-fine language modeling 论文明确表明,语音 token 预测主要依赖局部上下文,即所谓的“短程依赖”特性。
- 互信息分析证实了缠结性。 对 SpeechTokenizer 及相关 codec 的研究显示,音高、说话人身份和语言内容在 RVQ 各层之间是缠结的。第一层 RVQ(语义层)捕获语音内容;后续各层捕获韵律和音色。但在每一层内部,相邻 token 仍然因底层信号的连续性而共享大量互信息。

总之,我们的目标是按 token 的时间邻接关系和领域特定依赖结构进行分组。同组 token 是连续的。其分组反映的是信号的物理/语义结构,而不是模型状态。
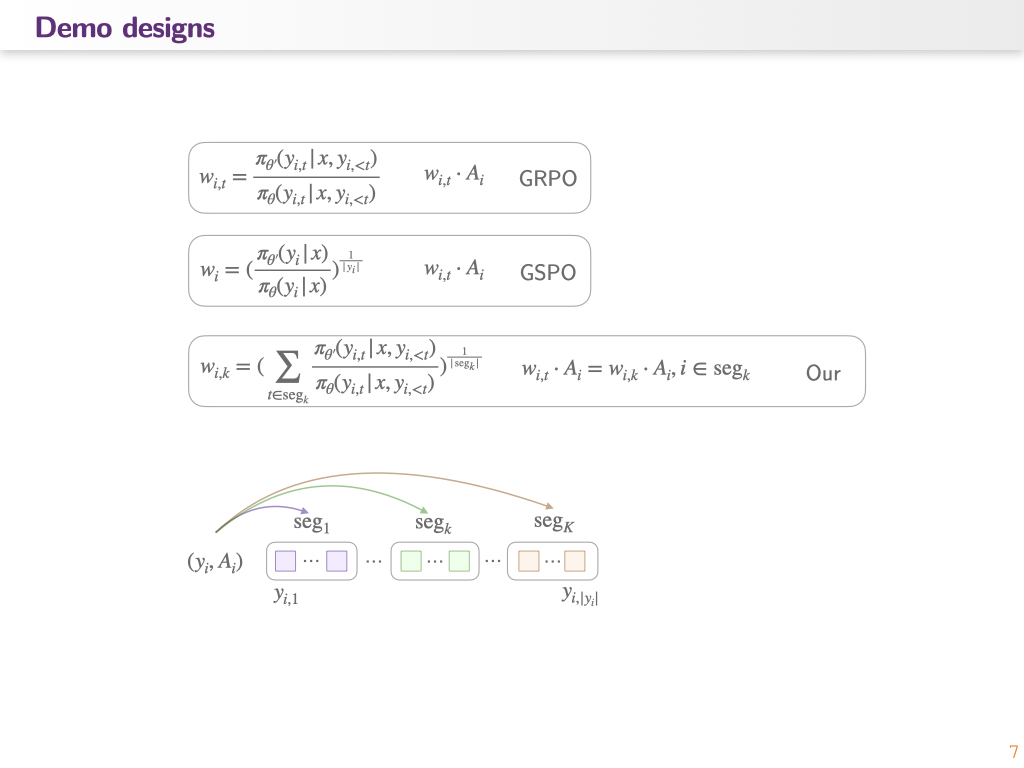
目前尝试的基本办法:
MASPO-Fixed: 固定窗口分段
实现:把生成的 completion 按固定窗口大小 $W$ 切分成 $\lceil T / W \rceil$ 个不重叠的 segment。每个 segment 内的所有 token 共享同一个 IS ratio。
原理:语音 codec token(XCodec2 @ 50Hz)天然存在多层级的物理时间尺度。$W = 5$ 对应约 100ms(一个音素的典型时长),$W = 15$ 对应约 300ms(一个音节),$W = 50$ 对应约 1s(一个韵律短语)。通过选择不同的 $W$,可以让 IS 的粒度 align 到不同的声学单元。
理论支撑:
核心论点是 segment 内的 token 高度相关,不是独立样本。IS 理论要求被校正的样本是从 proposal 分布独立采出的,但语音 codec token 在一个音素内部几乎是确定性的,formant trajectory 是连续的,模型 logprob 极高(entropy 接近 0)。对这些高度相关的 token 做 token-level IS 不仅理论上无效,还会引入不必要的方差。Fixed-window 是最简单的去相关策略:假设 W 个 token 内部相关性极高,segment 之间相对独立。
优势:实现极简(一行 torch.arange(T) // W),计算零开销,超参只有一个($W$),而且 $W = 1$ 退化为 GRPO、$W = T$ 退化为 GSPO,方便做消融实验扫描整个 granularity spectrum。
局限:固定窗口无法自适应实际的声学边界。一个音素可能跨 4 个 token 也可能跨 8 个,fixed window 会在音素中间切断或者把两个不同音素混在一起。
MASPO-LogProb: 基于 log-probability 跌落的自适应分段
原理:这个方法利用了一个物理事实,即 old policy 的 logprob 反映了 token 的可预测性。在一个音素内部,后续 token 基本由前面的 formant trajectory 决定,logprob 高且平稳;到了音素/音节边界,模型需要切换到一个新的声学单元,不确定性骤增,logprob 出现显著下降。所以 logprob drop 是一个天然的声学边界检测器。
理论支撑:
这个方法和 ESPO(Entropy-Sorted Policy Optimization)有相似的 motivation 但方向不同。ESPO 观察到 token 的 entropy 决定了它对 RL 学习的贡献,高 entropy token 是“forking point”,低 entropy token 几乎不影响 reward。MASPO-LogProb 的逻辑是互补的:不是按 entropy 值分组(ESPO 做的,非连续),而是用 entropy/logprob 的时间变化来找连续的声学边界。在语音里,连续性是本质性的,相邻 token 表示的是同一段物理声波,必须保持时间连续的 segment。
另一个理论优势是 zero extra computation,old policy 的 logprob 在 rollout 阶段已经计算好了(GRPO 本来就需要 $\pi_{\theta_{\text{old}}}$ 的 logprob 来算 IS ratio),所以 boundary detection 不需要任何额外的 forward pass。
优势:自适应、数据驱动的分段,能自动 align 到实际的声学边界;per-sample adaptive(用每个 sample 自己的 $\mu/\sigma$),对不同说话风格和语速鲁棒。
局限:threshold $\tau$ 的选择仍然是超参。$\tau$ 太大,段太粗(趋近 GSPO);$\tau$ 太小,段太细(趋近 GRPO)。另外 logprob drop 作为声学边界的 proxy 不是 100% 准确,有些边界模型预测得很好(常见音素转换),有些非边界位置模型可能突然困惑(罕见发音)。
MASPO-TokenVal: 基于 codec token ID 跳变的分段
原理:这个方法利用了 VQ codebook 的几何结构。XCodec2 的 codebook 通过 VQ 训练学到的 embedding 空间中,声学相似的信号倾向于映射到相近的 codebook index(这是 VQ-VAE 训练的副产品,K-means 风格的聚类使得空间局部性被部分保留)。因此:
- 同一个音素内部:声学特征(F0, formant, amplitude)变化平缓,连续帧映射到相近的 codebook entry,token ID 差值小。
- 声学转换点:新音素 onset、voicing 切换、pitch reset 等位置,声学特征突变,映射到 codebook 中较远的 entry,token ID 出现大幅跳变。
所以 $|id_t - id_{t-1}|$ 超过阈值可以作为声学边界的粗略 proxy。
理论支撑:
这个方法的合理性来自两个层面。第一,信息论层面:如果 codebook 的排列完全保留了声学距离(即 codebook index 的差和声学特征的差正相关),那么 token ID jump 就是声学距离的精确 proxy。实际上 VQ 训练不保证完美的 index 局部性,但实证上这种相关性通常存在,特别是对于 single-codebook 的 codec(XCodec2 就是)。第二,实践层面:这种方法完全不依赖模型的 logprob,只看 token 序列本身。这意味着它捕捉的是数据层面的声学结构,而不是模型层面的不确定性,和 LogProb 方法形成互补。
优势:计算极其轻量(一次减法加比较),不依赖任何模型输出(纯数据驱动),conceptually 最直觉。
局限:最大的问题是 VQ codebook 的 index 排列不保证声学连续性。标准的 VQ-VAE 训练(包括 XCodec2)用 K-means 或 EMA 更新 codebook,codebook entry 的 index 分配本质上是随机的,两个相邻 index 对应的声学特征可能完全不同。所以 token ID 差值作为声学距离的 proxy 理论上不可靠,需要在实际数据上做 calibration。如果 codebook 没有好的 index locality,这个方法会退化为近似随机分段。
欢迎交流
如果你想讨论这篇文章里的想法、实现细节或后续问题,欢迎提交 GitHub Issue,或通过 LinkedIn 联系我。
Chang ZENG 曾畅 曾 暢 (ソウ チョウ)
Senior Research Scientist
Senior Research Scientist in generative audio, voice LLMs, and multimodal AI, with experience from research to production.