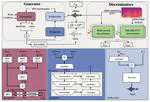
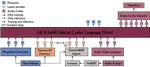
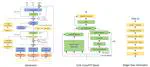
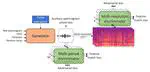
Generative AI
 Photo by rawpixel on Unsplash
Photo by rawpixel on UnsplashThe research topics cover text-to-audio (TTA), singing voice synthesis (SVS), music generation, and more multi-modality generative task in the future.
Chang ZENG 曾畅 曾 暢 (ソウ チョウ)
Senior Research Scientist
Senior Research Scientist in generative audio, voice LLMs, and multimodal AI, with experience from research to production.