Chang ZENG
Chang ZENG
Home
News
Publications
Skills
Activities
Experience
Posts
Light
Dark
Automatic
Publications
Type
Conference paper
Journal article
Preprint / Working Paper
Date
2026
2025
2024
2023
2022
2021
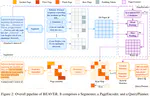
BEAVER: A Training-Free Hierarchical Prompt Compression Method via Structure-Aware Page Selection
BEAVER is a training-free hierarchical prompt compression framework for long-context LLM inference with strong benchmark performance and 26.4x lower latency on 128k contexts.
Zhengpei Hu
,
Kai Li
,
Dapeng Fu
,
Chang Zeng
,
Yue Li
,
Yuanhao Tang
,
Jianqiang Huang
PDF
Code
Project
Demo
ArXiv
Speech Codec Probing from Semantic and Phonetic Perspectives
We probe widely used speech tokenizers and show they encode phonetic structure much more strongly than lexical-semantic content.
Xuan Shi
,
Chang Zeng
,
Tiantian Feng
,
Shih-Heng Wang
,
Jianbo Ma
,
Shrikanth Narayanan
PDF
ArXiv
A Semantically Consistent Dataset for Data-Efficient Query-Based Universal Sound Separation
We propose Hive, a semantically consistent 2.4k-hour dataset for data-efficient universal sound separation with strong zero-shot generalization.
Kai Li
,
Jintao Cheng
,
Chang Zeng
,
Zijun Yan
,
Helin Wang
,
Zixiong Su
,
Bo Zheng
,
Xiaolin Hu
PDF
Code
Dataset
ArXiv
HF Dataset (3rd Party)
PAGS: Priority-Adaptive Gaussian Splatting for Dynamic Driving Scenes
PAGS uses semantic priorities in Gaussian Splatting to improve dynamic driving-scene quality and efficiency, achieving high fidelity with very fast rendering.
Wenzhang Sun
,
Chang Zeng
,
Chunfeng Wang
,
Hao Li
,
Jianxun Cui
PDF
ArXiv
DrivingScene: A Multi-Task Online Feed-Forward 3D Gaussian Splatting Method for Dynamic Driving Scenes
DrivingScene reconstructs dynamic 4D driving scenes online from two surround-view frames with strong quality and efficiency.
Qirui Hou
,
Wenzhang Sun
,
Chang Zeng
,
Chunfeng Wang
,
Hao Li
,
Jianxun Cui
PDF
ArXiv
Towards Interactive Intelligence for Digital Humans
Mio is an end-to-end multimodal interactive digital-human framework that combines reasoning and real-time embodiment with state-of-the-art performance.
Yiyi Cai
,
Xuangeng Chu
,
Xiwei Gao
,
Sitong Gong
,
Yifei Huang
,
Caixin Kang
,
Kunhang Li
,
Haiyang Liu
,
Ruicong Liu
,
Yun Liu
,
Dianwen Ng
,
Zixiong Su
,
Erwin Wu
,
Yuhan Wu
,
Dingkun Yan
,
Tianyu Yan
,
Chang Zeng
,
Bo Zheng
,
You Zhou
PDF
Project
ArXiv
Demo
Critical Information Only: A Content Privacy-Preserving Framework for Detecting Audio Deepfakes
SafeEar detects audio deepfakes with strong performance while preserving content privacy by decoupling and suppressing semantic information.
Xinfeng Li
,
Yifan Zheng
,
Chen Yan
,
Kai Li
,
Chang Zeng
,
Xiaoyu Ji
,
Wenyuan Xu
PDF
SonicSim: A Customizable Simulation Platform for Speech Processing in Moving Sound Source Scenarios
SonicSim is a customizable simulation toolkit and benchmark that improves real-world generalization for moving-source speech processing.
Kai Li
,
Wendi Sang
,
Chang Zeng
,
Runxuan Yang
,
Guo Chen
,
Xiaolin Hu
PDF
Code
ArXiv
A Benchmark for Multi-Speaker Anonymization
This work establishes an initial benchmark and baseline systems for multi-speaker anonymization, including conversation-level anonymization strategies.
Xiaoxiao Miao
,
Ruijie Tao
,
Chang Zeng
,
Xin Wang
PDF
InstructSing: High-Fidelity Singing Voice Generation via Instructing Yourself
This paper presents a novel neural vocoder called InstructSing, which can converge much faster compared with other neural vocoders while maintaining good performance by integrating differentiable digital signal processing and adversarial training.
Chang Zeng
,
Chunhui Wang
,
Xiaoxiao Miao
,
Jian Zhao
,
Zhonglin Jiang
,
Yong Chen
PDF
Cite
Project
DOI
SLT2024
Spoofing-Aware Speaker Verification Robust Against Domain and Channel Mismatches
We propose an integrated spoofing-aware ASV framework robust to domain and channel mismatch, with strong gains on the CNComplex benchmark.
Chang Zeng
,
Xiaoxiao Miao
,
Xin Wang
,
Erica Cooper
,
Junichi Yamagishi
PDF
HAM-TTS: Hierarchical Acoustic Modeling for Token-Based Zero-Shot Text-to-Speech with Model and Data Scaling
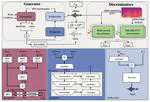
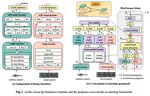
We introduce a novel token-based text-to-speech (TTS) model with 0.8B parameters, trained on a mix of real and synthetic data totaling 650k hours, to address issues like pronunciation accuracy and style consistency. This model integrates a latent variable sequence with enhanced acoustic information into the TTS system, reducing errors and style changes. Our training includes data augmentation for improved timbre consistency, and we use a few-shot voice conversion model to generate diverse voices. This approach enables learning of one-to-many mappings in speech, ensuring both diversity and timbre consistency. Our model outperforms VALL-E in pronunciation, style maintenance, and timbre continuity.
Chunhui Wang
,
Chang Zeng
,
Bowen Zhang
,
Ziyang Ma
,
Yefan Zhu
,
Zifeng Cai
,
Jian Zhao
,
Zhonglin Jiang
,
Yong Chen
PDF
Cite
Project
DOI
ArXiv
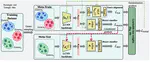
Joint Speaker Encoder and Neural Back-end Model for Fully End-to-End Automatic Speaker Verification with Multiple Enrollment Utterances
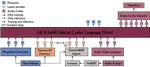
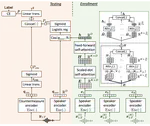
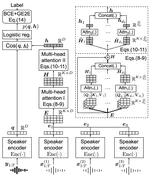
We propose a new end-to-end (E2E) method for automatic speaker verification, specifically tailored for scenarios with multiple enrollment utterances. Unlike conventional systems, which separately optimize front-end models like TDNN for speaker embeddings and back-end models like PLDA for scoring, our approach aims to overcome local optimization limits by jointly optimizing these components. Our model incorporates frame-level and utterance-level attention mechanisms to leverage the relationships among multiple utterances. Additionally, we enhance optimization through data augmentation techniques, including conventional noise augmentation with MUSAN and RIRs datasets, and a novel speaker embedding-level mixup strategy.
Chang Zeng
,
Xiaoxiao Miao
,
Xin Wang
,
Erica Cooper
,
Junichi Yamagishi
PDF
Cite
Dataset
Project
DOI
CSL
HiFi-WaveGAN: Generative Adversarial Network with Auxiliary Spectrogram-Phase Loss for High-Fidelity Singing Voice Generation
This paper introduces HiFi-WaveGAN, a system designed for real-time synthesis of high-quality 48kHz singing voices from full-band mel-spectrograms. It improves upon WaveNet with a generator, incorporates elements from HiFiGAN and UnivNet, and introduces an auxiliary spectrogram-phase loss to enhance high-frequency reconstruction and accelerate training. HiFi-WaveGAN outperforms other neural vocoders like Parallel WaveGAN and HiFiGAN in quality metrics, with faster training and better high-frequency modeling.
Chunhui Wang
,
Chang Zeng
,
Jun Chen
,
Yuhao Wang
,
Xing He
PDF
Cite
Project
DOI
ArXiv
CrossSinger: A Cross-Lingual Multi-Singer High-Fidelity Singing Voice Synthesizer Trained on Monolingual Singers
This paper presents CrossSinger, a cross-lingual singing voice synthesizer based on Xiaoicesing2. It tackles the challenge of creating a multi-singer high-fidelity singing voice synthesis system with cross-lingual capabilities using only monolingual singers during training. The system unifies language representation, incorporates language information, and removes singer biases. Experimental results show that CrossSinger can synthesize high-quality songs for different singers in various languages, including code-switching cases.
Xintong Wang
,
Chang Zeng
,
Jun Chen
,
Chunhui Wang
PDF
Cite
Code
Dataset
Project
ASRU2023
Xiaoicesing 2: A High-Fidelity Singing Voice Synthesizer Based on Generative Adversarial Network
This paper presents XiaoiceSing2, an enhanced singing voice synthesis system that addresses over-smoothing issues in middle- and high-frequency areas of mel-spectrograms. It employs a generative adversarial network (GAN) with improved model architecture to capture finer details.
Chunhui Wang
,
Chang Zeng
,
Xing He
PDF
Cite
Code
Dataset
Project
DOI
Interspeech2023
Improving Generalization Ability of Countermeasures for New Mismatch Scenario by Combining Multiple Advanced Regularization Terms
The ability of countermeasure models to generalize from seen speech synthesis methods to unseen ones has been investigated in the ASVspoof challenge. However, a new mismatch scenario in which fake audio may be generated from real audio with unseen genres has not been studied thoroughly. To this end, we first use five different vocoders to create a new dataset called CN-Spoof based on the CN-Celeb1&2 datasets. Then, we design two auxiliary objectives for regularization via meta-optimization and a genre alignment module, respectively, and combine them with the main anti-spoofing objective using learnable weights for multiple loss terms.
Chang Zeng
,
Xin Wang
,
Xiaoxiao Miao
,
Erica Cooper
,
Junichi Yamagishi
PDF
Cite
Code
Project
DOI
Interspeech2023
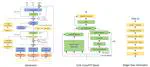
Beyond Universal Transformer: block reusing with adaptor in Transformer for automatic speech recognition
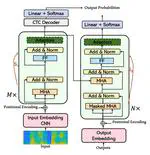
Recent advances in Transformer-based models have enhanced end-to-end automatic speech recognition (ASR), enabling deployment on smart devices. However, these models often require large numbers of parameters. To address this, we introduce a block-reusing strategy for speech Transformers (BRST) and an adapter module (ADM) for efficient parameter use in small footprint ASR systems, without sacrificing accuracy. Tested on the AISHELL-1 corpus, our method achieved low character error rates with significantly fewer parameters, demonstrating both efficiency and effectiveness, particularly with the inclusion of ADM.
Haoyu Tang
,
Zhaoyi Liu
,
Chang Zeng
,
Xinfeng Li
PDF
Cite
DOI
ArXiv
SSI-Net: A Multi-Stage Speech Signal Improvement System for ICASSP 2023 SSI Challenge
We introduce SSI-Net, our submission to the ICASSP 2023 Speech Signal Improvement (SSI) Challenge, designed for real-time communication systems. SSI-Net features a multi-stage architecture, beginning with a time-domain restoration generative adversarial network (TRGAN) for initial speech restoration. In the second stage, we use a lightweight multi-scale temporal frequency convolutional network with axial self-attention (MTFAA-Lite) for fullband speech enhancement. In subjective tests on the SSI Challenge blind test set, SSI-Net achieved a P.835 mean opinion score (MOS) of 3.190 and a P.804 MOS of 3.178, ranking 3rd in tracks 1&2.
Weixin Zhu
,
Zilin Wang
,
Jiuxin Lin
,
Chang Zeng
,
Tao Yu
PDF
Cite
Project
DOI
ICASSP Link
Cross-Modal Audio-Visual Co-Learning for Text-Independent Speaker Verification
Visual speech (i.e., lip motion) is highly related to auditory speech due to the co-occurrence and synchronization in speech production. This paper investigates this correlation and proposes a cross-modal speech co-learning paradigm. The primary motivation of our cross-modal co-learning method is modeling one modality aided by exploiting knowledge from another modality. Specifically, two cross-modal boosters are introduced based on an audio-visual pseudo-siamese structure to learn the modality-transformed correlation. Inside each booster, a max-feature-map embedded Transformer variant is proposed for modality alignment and enhanced feature generation. The network is co-learned both from scratch and with pretrained models. Experimental results on the test scenarios demonstrate that our proposed method achieves around 60% and 20% average relative performance improvement over baseline unimodal and fusion systems, respectively.
Meng Liu
,
Kong Aik Lee
,
Longbiao Wang
,
Hanyi Zhang
,
Chang Zeng
,
Jianwu Dang
PDF
Cite
Project
DOI
ICASSP
Deep Spectro-temporal Artifacts for Detecting Synthesized Speech
Audio Deep Synthesis Detection, Spectro-temporal, Domain Adaptation, Self-Supervised Learning, Frame transition, Greedy Fusion.
Xiaohui Liu
,
Meng Liu
,
Lin Zhang
,
Linjuan Zhang
,
Chang Zeng
,
Kai Li
,
Nan Li
,
Kong Aik Lee
,
Longbiao Wang
,
Jianwu Dang
PDF
Cite
Project
DOI
ACMMM Link
Spoofing-Aware Attention based ASV Back-end with Multiple Enrollment Utterances and a Sampling Strategy for the SASV Challenge 2022
Current state-of-the-art automatic speaker verification (ASV) systems are vulnerable to presentation attacks, and several countermeasures (CMs), which distinguish bona fide trials from spoofing ones, have been explored to protect ASV. However, ASV systems and CMs are generally developed and optimized independently without considering their inter-relationship. In this paper, we propose a new spoofing-aware ASV back-end module that efficiently computes a combined ASV score based on speaker similarity and CM score.
Chang Zeng
,
Lin Zhang
,
Meng Liu
,
Junichi Yamagishi
PDF
Cite
Project
Video
DOI
INTERSPEECH Link
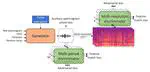
Data Augmentation Using McAdams-Coefficient-Based Speaker Anonymization for Fake Audio Detection
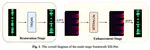
We propose a fake audio detection (FAD) system using speaker anonymization (SA) to enhance the distinction between synthetic and natural speech. The key strategy is to remove speaker-specific information from acoustic speech before it’s processed by a deep neural network (DNN)-based FAD system. We employed the McAdams-coefficient-based SA algorithm to ensure that speaker information doesn’t influence DNN learning. Our system, based on a light convolutional neural network bidirectional long short-term memory (LCNN-BLSTM), was tested on the Audio Deep Synthesis Detection Challenge (ADD2022) datasets. Results indicate a 17.66% performance improvement in the first track of ADD2022 by eliminating speaker information from the acoustic speech.
Kai Li
,
Sheng Li
,
Xugang Lu
,
Masato Akagi
,
Meng Liu
,
Lin Zhang
,
Chang Zeng
,
Longbiao Wang
,
Jianwu Dang
,
Masashi Unoki
PDF
Cite
Project
DOI
INTERSPEECH Link
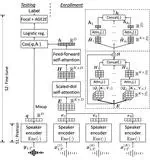
Attention Back-end for Automatic Speaker Verification with Multiple Enrollment Utterances
Probabilistic linear discriminant analysis (PLDA) or cosine similarity has been widely used in traditional speaker verification systems as a back-end technique to measure pairwise similarities. To make better use of multiple enrollment utterances, we propose a novel attention back-end model that is applied to the utterance-level features. Specifically, we use scaled-dot self-attention and feed-forward self-attention networks as architectures that learn the intra-relationships of enrollment utterances.
Chang Zeng
,
Xin Wang
,
Erica Cooper
,
Xiaoxiao Miao
,
Junichi Yamagishi
PDF
Cite
Code
Dataset
Project
Video
DOI
ICASSP
DeepLip: A Benchmark for Deep Learning-Based Audio-Visual Lip Biometrics
speaker recognition, audio-visual, lip biometrics, deep learning, visual speech.
Meng Liu
,
Longbiao Wang
,
Kong Aik Lee
,
Hanyi Zhang
,
Chang Zeng
,
Jianwu Dang
PDF
Cite
Project
DOI
ASRU Link
Cite
×