Chang ZENG
Chang ZENG
Home
News
Publications
Skills
Activities
Experience
Posts
Light
Dark
Automatic
1
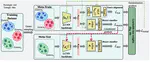
DrivingScene: A Multi-Task Online Feed-Forward 3D Gaussian Splatting Method for Dynamic Driving Scenes
DrivingScene reconstructs dynamic 4D driving scenes online from two surround-view frames with strong quality and efficiency.
Qirui Hou
,
Wenzhang Sun
,
Chang Zeng
,
Chunfeng Wang
,
Hao Li
,
Jianxun Cui
PDF
ArXiv
PAGS: Priority-Adaptive Gaussian Splatting for Dynamic Driving Scenes
PAGS uses semantic priorities in Gaussian Splatting to improve dynamic driving-scene quality and efficiency, achieving high fidelity with very fast rendering.
Wenzhang Sun
,
Chang Zeng
,
Chunfeng Wang
,
Hao Li
,
Jianxun Cui
PDF
ArXiv
SonicSim: A Customizable Simulation Platform for Speech Processing in Moving Sound Source Scenarios
SonicSim is a customizable simulation toolkit and benchmark that improves real-world generalization for moving-source speech processing.
Kai Li
,
Wendi Sang
,
Chang Zeng
,
Runxuan Yang
,
Guo Chen
,
Xiaolin Hu
PDF
Code
ArXiv
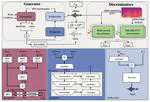
InstructSing: High-Fidelity Singing Voice Generation via Instructing Yourself
This paper presents a novel neural vocoder called InstructSing, which can converge much faster compared with other neural vocoders while maintaining good performance by integrating differentiable digital signal processing and adversarial training.
Chang Zeng
,
Chunhui Wang
,
Xiaoxiao Miao
,
Jian Zhao
,
Zhonglin Jiang
,
Yong Chen
PDF
Cite
Project
DOI
SLT2024
Spoofing-Aware Speaker Verification Robust Against Domain and Channel Mismatches
We propose an integrated spoofing-aware ASV framework robust to domain and channel mismatch, with strong gains on the CNComplex benchmark.
Chang Zeng
,
Xiaoxiao Miao
,
Xin Wang
,
Erica Cooper
,
Junichi Yamagishi
PDF
CrossSinger: A Cross-Lingual Multi-Singer High-Fidelity Singing Voice Synthesizer Trained on Monolingual Singers
This paper presents CrossSinger, a cross-lingual singing voice synthesizer based on Xiaoicesing2. It tackles the challenge of creating a multi-singer high-fidelity singing voice synthesis system with cross-lingual capabilities using only monolingual singers during training. The system unifies language representation, incorporates language information, and removes singer biases. Experimental results show that CrossSinger can synthesize high-quality songs for different singers in various languages, including code-switching cases.
Xintong Wang
,
Chang Zeng
,
Jun Chen
,
Chunhui Wang
PDF
Cite
Code
Dataset
Project
ASRU2023
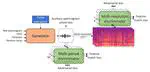
HiFi-WaveGAN: Generative Adversarial Network with Auxiliary Spectrogram-Phase Loss for High-Fidelity Singing Voice Generation
This paper introduces HiFi-WaveGAN, a system designed for real-time synthesis of high-quality 48kHz singing voices from full-band mel-spectrograms. It improves upon WaveNet with a generator, incorporates elements from HiFiGAN and UnivNet, and introduces an auxiliary spectrogram-phase loss to enhance high-frequency reconstruction and accelerate training. HiFi-WaveGAN outperforms other neural vocoders like Parallel WaveGAN and HiFiGAN in quality metrics, with faster training and better high-frequency modeling.
Chunhui Wang
,
Chang Zeng
,
Jun Chen
,
Yuhao Wang
,
Xing He
PDF
Cite
Project
DOI
ArXiv
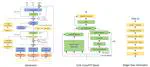
Improving Generalization Ability of Countermeasures for New Mismatch Scenario by Combining Multiple Advanced Regularization Terms
The ability of countermeasure models to generalize from seen speech synthesis methods to unseen ones has been investigated in the ASVspoof challenge. However, a new mismatch scenario in which fake audio may be generated from real audio with unseen genres has not been studied thoroughly. To this end, we first use five different vocoders to create a new dataset called CN-Spoof based on the CN-Celeb1&2 datasets. Then, we design two auxiliary objectives for regularization via meta-optimization and a genre alignment module, respectively, and combine them with the main anti-spoofing objective using learnable weights for multiple loss terms.
Chang Zeng
,
Xin Wang
,
Xiaoxiao Miao
,
Erica Cooper
,
Junichi Yamagishi
PDF
Cite
Code
Project
DOI
Interspeech2023
Xiaoicesing 2: A High-Fidelity Singing Voice Synthesizer Based on Generative Adversarial Network
This paper presents XiaoiceSing2, an enhanced singing voice synthesis system that addresses over-smoothing issues in middle- and high-frequency areas of mel-spectrograms. It employs a generative adversarial network (GAN) with improved model architecture to capture finer details.
Chunhui Wang
,
Chang Zeng
,
Xing He
PDF
Cite
Code
Dataset
Project
DOI
Interspeech2023
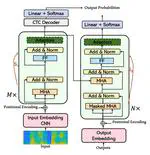
Beyond Universal Transformer: block reusing with adaptor in Transformer for automatic speech recognition
Recent advances in Transformer-based models have enhanced end-to-end automatic speech recognition (ASR), enabling deployment on smart devices. However, these models often require large numbers of parameters. To address this, we introduce a block-reusing strategy for speech Transformers (BRST) and an adapter module (ADM) for efficient parameter use in small footprint ASR systems, without sacrificing accuracy. Tested on the AISHELL-1 corpus, our method achieved low character error rates with significantly fewer parameters, demonstrating both efficiency and effectiveness, particularly with the inclusion of ADM.
Haoyu Tang
,
Zhaoyi Liu
,
Chang Zeng
,
Xinfeng Li
PDF
Cite
DOI
ArXiv
»
Cite
×