Chang ZENG
Chang ZENG
Home
News
Publications
Skills
Activities
Experience
Posts
Light
Dark
Automatic
2
Critical Information Only: A Content Privacy-Preserving Framework for Detecting Audio Deepfakes
SafeEar detects audio deepfakes with strong performance while preserving content privacy by decoupling and suppressing semantic information.
Xinfeng Li
,
Yifan Zheng
,
Chen Yan
,
Kai Li
,
Chang Zeng
,
Xiaoyu Ji
,
Wenyuan Xu
PDF
A Benchmark for Multi-Speaker Anonymization
This work establishes an initial benchmark and baseline systems for multi-speaker anonymization, including conversation-level anonymization strategies.
Xiaoxiao Miao
,
Ruijie Tao
,
Chang Zeng
,
Xin Wang
PDF
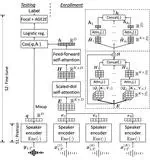
Joint Speaker Encoder and Neural Back-end Model for Fully End-to-End Automatic Speaker Verification with Multiple Enrollment Utterances
We propose a new end-to-end (E2E) method for automatic speaker verification, specifically tailored for scenarios with multiple enrollment utterances. Unlike conventional systems, which separately optimize front-end models like TDNN for speaker embeddings and back-end models like PLDA for scoring, our approach aims to overcome local optimization limits by jointly optimizing these components. Our model incorporates frame-level and utterance-level attention mechanisms to leverage the relationships among multiple utterances. Additionally, we enhance optimization through data augmentation techniques, including conventional noise augmentation with MUSAN and RIRs datasets, and a novel speaker embedding-level mixup strategy.
Chang Zeng
,
Xiaoxiao Miao
,
Xin Wang
,
Erica Cooper
,
Junichi Yamagishi
PDF
Cite
Dataset
Project
DOI
CSL
Cite
×