Chang ZENG
Chang ZENG
Home
News
Publications
Skills
Activities
Experience
Posts
Light
Dark
Automatic
3
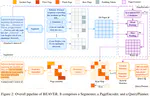
BEAVER: A Training-Free Hierarchical Prompt Compression Method via Structure-Aware Page Selection
BEAVER is a training-free hierarchical prompt compression framework for long-context LLM inference with strong benchmark performance and 26.4x lower latency on 128k contexts.
Zhengpei Hu
,
Kai Li
,
Dapeng Fu
,
Chang Zeng
,
Yue Li
,
Yuanhao Tang
,
Jianqiang Huang
PDF
Code
Project
Demo
ArXiv
Speech Codec Probing from Semantic and Phonetic Perspectives
We probe widely used speech tokenizers and show they encode phonetic structure much more strongly than lexical-semantic content.
Xuan Shi
,
Chang Zeng
,
Tiantian Feng
,
Shih-Heng Wang
,
Jianbo Ma
,
Shrikanth Narayanan
PDF
ArXiv
A Semantically Consistent Dataset for Data-Efficient Query-Based Universal Sound Separation
We propose Hive, a semantically consistent 2.4k-hour dataset for data-efficient universal sound separation with strong zero-shot generalization.
Kai Li
,
Jintao Cheng
,
Chang Zeng
,
Zijun Yan
,
Helin Wang
,
Zixiong Su
,
Bo Zheng
,
Xiaolin Hu
PDF
Code
Dataset
ArXiv
HF Dataset (3rd Party)
Towards Interactive Intelligence for Digital Humans
Mio is an end-to-end multimodal interactive digital-human framework that combines reasoning and real-time embodiment with state-of-the-art performance.
Yiyi Cai
,
Xuangeng Chu
,
Xiwei Gao
,
Sitong Gong
,
Yifei Huang
,
Caixin Kang
,
Kunhang Li
,
Haiyang Liu
,
Ruicong Liu
,
Yun Liu
,
Dianwen Ng
,
Zixiong Su
,
Erwin Wu
,
Yuhan Wu
,
Dingkun Yan
,
Tianyu Yan
,
Chang Zeng
,
Bo Zheng
,
You Zhou
PDF
Project
ArXiv
Demo
HAM-TTS: Hierarchical Acoustic Modeling for Token-Based Zero-Shot Text-to-Speech with Model and Data Scaling
We introduce a novel token-based text-to-speech (TTS) model with 0.8B parameters, trained on a mix of real and synthetic data totaling 650k hours, to address issues like pronunciation accuracy and style consistency. This model integrates a latent variable sequence with enhanced acoustic information into the TTS system, reducing errors and style changes. Our training includes data augmentation for improved timbre consistency, and we use a few-shot voice conversion model to generate diverse voices. This approach enables learning of one-to-many mappings in speech, ensuring both diversity and timbre consistency. Our model outperforms VALL-E in pronunciation, style maintenance, and timbre continuity.
Chunhui Wang
,
Chang Zeng
,
Bowen Zhang
,
Ziyang Ma
,
Yefan Zhu
,
Zifeng Cai
,
Jian Zhao
,
Zhonglin Jiang
,
Yong Chen
PDF
Cite
Project
DOI
ArXiv
Cite
×