BEAVER: A Training-Free Hierarchical Prompt Compression Method via Structure-Aware Page Selection
Abstract
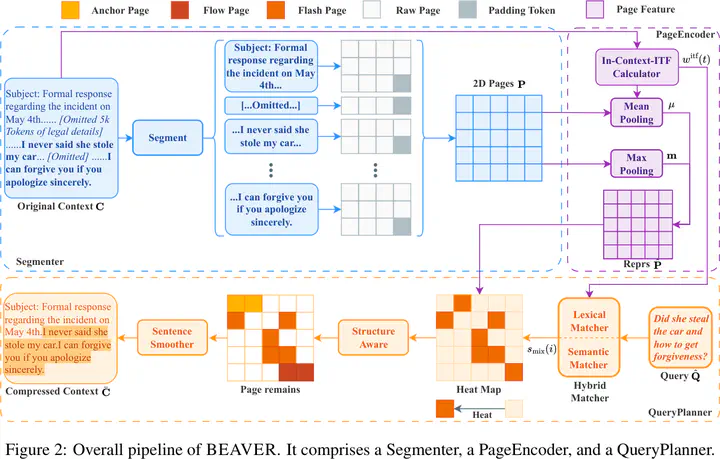
The exponential expansion of context windows in LLMs has unlocked capabilities for long-document understanding but introduced severe bottlenecks in inference latency and information utilization. Existing compression methods often suffer from high training costs or semantic fragmentation due to aggressive token pruning. We propose BEAVER, a training-free framework that shifts compression from linear token removal to structure-aware hierarchical selection. BEAVER maps variable-length contexts into dense page-level tensors via dual-path pooling and preserves discourse integrity through a hybrid planner that combines semantic and lexical dual-branch selection with sentence smoothing. Across four long-context benchmarks, it achieves performance comparable to strong baselines while reducing latency by 26.4x on 128k contexts.