A Semantically Consistent Dataset for Data-Efficient Query-Based Universal Sound Separation
Abstract
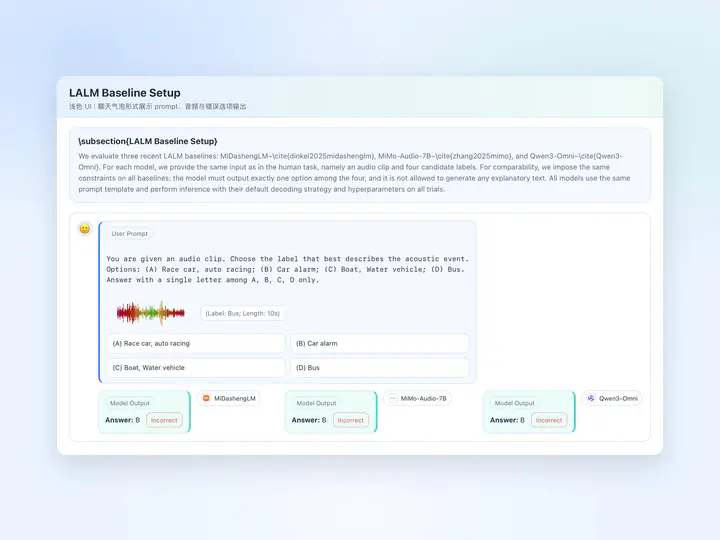
Query-based universal sound separation is fundamental to intelligent auditory systems, aiming to isolate specific sources from mixtures. Despite recent advances, existing methods still suffer from residual interference in complex acoustic scenes, largely due to weak labels and severe event co-occurrence in in-the-wild datasets. To address this, we propose an automated semantically consistent synthesis pipeline that mines high-purity single-event segments and removes spurious co-occurrence patterns. Using this pipeline, we construct Hive, a high-quality synthetic dataset with 2.4k hours of raw audio. Experiments show that open-source models trained on Hive can achieve competitive separation accuracy and perceptual quality, while demonstrating strong zero-shot generalization on out-of-distribution benchmarks.