DeepLip: A Benchmark for Deep Learning-Based Audio-Visual Lip Biometrics
Abstract
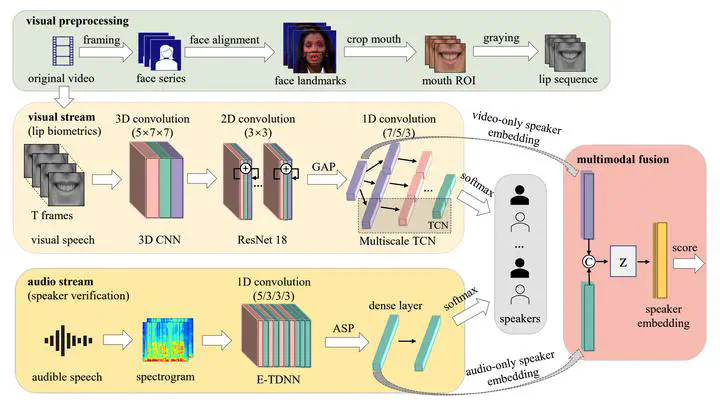
Audio-visual lip biometrics (AV-LB) has been an emerging biometrics technology that straddles auditory and visual speech processing. Previous works mainly focused on the front-end lip-based feature engineering combined with a shallow statistical back-end model. Over the past decade, convolutional neural network (CNN, or ConvNet) has been widely used and achieved good performance in computer vision and speech processing tasks. However, the lack of a sizeable public AV-LB database led to a stagnation in deep-learning exploration on AV-LB tasks. In addition to the dual audio-visual streams, one essential requirement on the video stream is the region of interest (ROI) around the lips has to be of sufficient resolution. To this end, we compile a moderate-size database using existing public databases. Using this database, we present a deep learning-based AV-LB benchmark, dubbed DeepLip 1 1 https://github.com/DanielMengLiu/DeepLip, realized with convolutional video and audio unimodal modules, and a multimodal fusion module. Our experiments show that DeepLip outperforms the traditional lip-biometrics system in context modeling and achieves over 50% relative improvements compared with its unimodal system, with an equal error rate of 0.75% and 1.11% on the test datasets, respectively.