HiFi-WaveGAN: Generative Adversarial Network with Auxiliary Spectrogram-Phase Loss for High-Fidelity Singing Voice Generation
Abstract
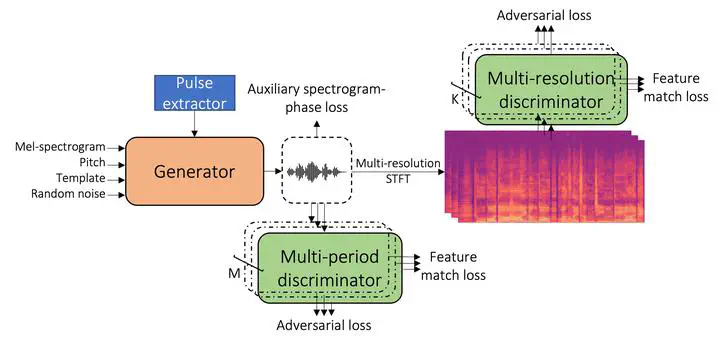
Entertainment-oriented singing voice synthesis (SVS) requires a vocoder to generate high-fidelity (e.g. 48kHz) audio. However, most text-to-speech (TTS) vocoders cannot work well in this scenario even if the neural vocoder for TTS has achieved significant progress. In this paper, we propose HiFi-WaveGAN which is designed for synthesizing the 48kHz high-quality singing voices from the full-band mel-spectrogram in real-time. Specifically, it consists of a generator improved from WaveNet, a multi-period discriminator same to HiFiGAN, and a multi-resolution spectrogram discriminator borrowed from UnivNet. To better reconstruct the high-frequency part from the full-band mel-spectrogram, we design a novel auxiliary spectrogram-phase loss to train the neural network, which can also accelerate the training process. The experimental result shows that our proposed HiFi-WaveGAN significantly outperforms other neural vocoders such as Parallel WaveGAN (PWG) and HiFiGAN in the mean opinion score (MOS) metric for the 48kHz SVS task. And a comparative study of HiFi-WaveGAN with/without phase loss term proves that phase loss indeed improves the training speed. Besides, we also compare the spectrogram generated by our HiFi-WaveGAN and PWG, which shows our HiFi-WaveGAN has a more powerful ability to model the high-frequency parts.