Attention Back-end for Automatic Speaker Verification with Multiple Enrollment Utterances
Abstract
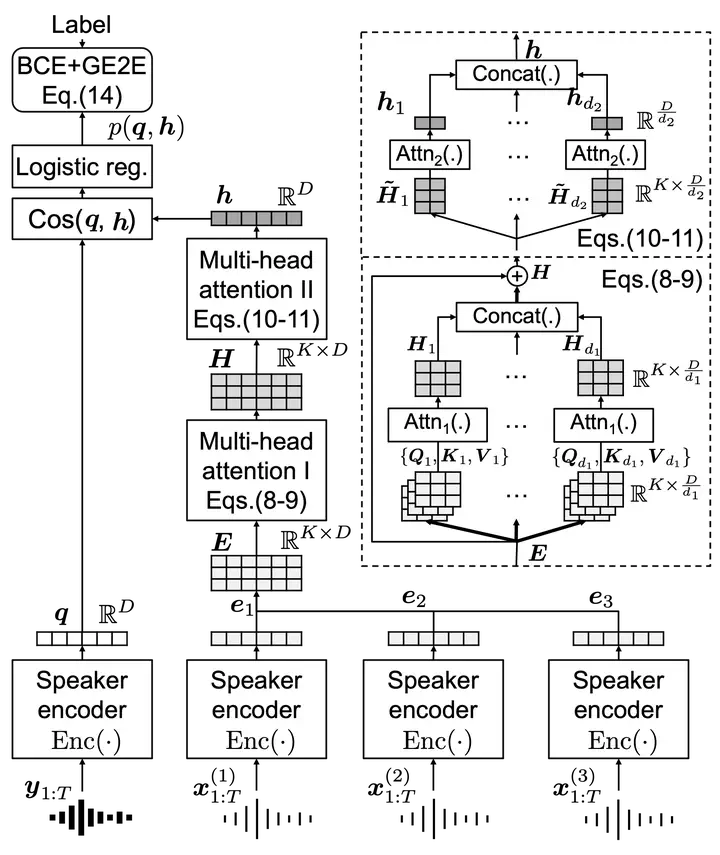
Probabilistic linear discriminant analysis (PLDA) or cosine similarity has been widely used in traditional speaker verification systems as a back-end technique to measure pairwise similarities. To make better use of multiple enrollment utterances, we propose a novel attention back-end model that is applied to the utterance-level features. Specifically, we use scaled-dot self-attention and feed-forward self-attention networks as architectures that learn the intra-relationships of enrollment utterances. To verify the proposed model, we conduct a series of experiments on the CNCeleb and VoxCeleb datasets by combining them with several state-of-the-art speaker encoders including TDNN and ResNet. Experimental results obtained using multiple enrollment utterances on CNCeleb show that the proposed attention back-end model leads to lower EER and minDCF scores than its PLDA and cosine similarity counterparts for each speaker encoder, and an experiment on VoxCeleb demonstrates that our model can be used even for a single enrollment case.