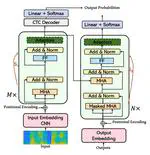
Recent advances in Transformer-based models have enhanced end-to-end automatic speech recognition (ASR), enabling deployment on smart devices. However, these models often require large numbers of parameters. To address this, we introduce a block-reusing strategy for speech Transformers (BRST) and an adapter module (ADM) for efficient parameter use in small footprint ASR systems, without sacrificing accuracy. Tested on the AISHELL-1 corpus, our method achieved low character error rates with significantly fewer parameters, demonstrating both efficiency and effectiveness, particularly with the inclusion of ADM.
Haoyu Tang, Zhaoyi Liu, Chang Zeng, Xinfeng Li