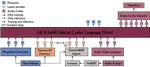
We introduce a novel token-based text-to-speech (TTS) model with 0.8B parameters, trained on a mix of real and synthetic data totaling 650k hours, to address issues like pronunciation accuracy and style consistency. This model integrates a latent variable sequence with enhanced acoustic information into the TTS system, reducing errors and style changes. Our training includes data augmentation for improved timbre consistency, and we use a few-shot voice conversion model to generate diverse voices. This approach enables learning of one-to-many mappings in speech, ensuring both diversity and timbre consistency. Our model outperforms VALL-E in pronunciation, style maintenance, and timbre continuity.
Chunhui Wang, Chang Zeng, Bowen Zhang, Ziyang Ma, Yefan Zhu, Zifeng Cai, Jian Zhao, Zhonglin Jiang, Yong Chen