Chang ZENG
Chang ZENG
Home
News
Publications
Skills
Activities
Experience
Posts
Light
Dark
Automatic
Singing Voice Synthesis
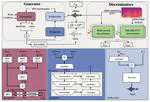
InstructSing: High-Fidelity Singing Voice Generation via Instructing Yourself
This paper presents a novel neural vocoder called InstructSing, which can converge much faster compared with other neural vocoders while maintaining good performance by integrating differentiable digital signal processing and adversarial training.
Chang Zeng
,
Chunhui Wang
,
Xiaoxiao Miao
,
Jian Zhao
,
Zhonglin Jiang
,
Yong Chen
PDF
Cite
Project
DOI
SLT2024
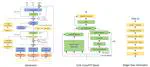
CrossSinger: A Cross-Lingual Multi-Singer High-Fidelity Singing Voice Synthesizer Trained on Monolingual Singers
This paper presents CrossSinger, a cross-lingual singing voice synthesizer based on Xiaoicesing2. It tackles the challenge of creating a multi-singer high-fidelity singing voice synthesis system with cross-lingual capabilities using only monolingual singers during training. The system unifies language representation, incorporates language information, and removes singer biases. Experimental results show that CrossSinger can synthesize high-quality songs for different singers in various languages, including code-switching cases.
Xintong Wang
,
Chang Zeng
,
Jun Chen
,
Chunhui Wang
PDF
Cite
Code
Dataset
Project
ASRU2023
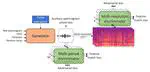
HiFi-WaveGAN: Generative Adversarial Network with Auxiliary Spectrogram-Phase Loss for High-Fidelity Singing Voice Generation
This paper introduces HiFi-WaveGAN, a system designed for real-time synthesis of high-quality 48kHz singing voices from full-band mel-spectrograms. It improves upon WaveNet with a generator, incorporates elements from HiFiGAN and UnivNet, and introduces an auxiliary spectrogram-phase loss to enhance high-frequency reconstruction and accelerate training. HiFi-WaveGAN outperforms other neural vocoders like Parallel WaveGAN and HiFiGAN in quality metrics, with faster training and better high-frequency modeling.
Chunhui Wang
,
Chang Zeng
,
Jun Chen
,
Yuhao Wang
,
Xing He
PDF
Cite
Project
DOI
ArXiv
Xiaoicesing 2: A High-Fidelity Singing Voice Synthesizer Based on Generative Adversarial Network
This paper presents XiaoiceSing2, an enhanced singing voice synthesis system that addresses over-smoothing issues in middle- and high-frequency areas of mel-spectrograms. It employs a generative adversarial network (GAN) with improved model architecture to capture finer details.
Chunhui Wang
,
Chang Zeng
,
Xing He
PDF
Cite
Code
Dataset
Project
DOI
Interspeech2023
Cite
×