Chang ZENG
Chang ZENG
Home
News
Publications
Skills
Activities
Experience
Posts
Light
Dark
Automatic
Speaker Recognition / Antispoofing
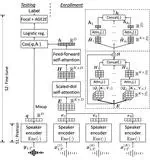
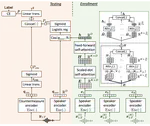
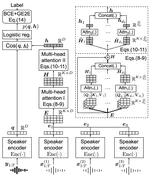
Joint Speaker Encoder and Neural Back-end Model for Fully End-to-End Automatic Speaker Verification with Multiple Enrollment Utterances
We propose a new end-to-end (E2E) method for automatic speaker verification, specifically tailored for scenarios with multiple enrollment utterances. Unlike conventional systems, which separately optimize front-end models like TDNN for speaker embeddings and back-end models like PLDA for scoring, our approach aims to overcome local optimization limits by jointly optimizing these components. Our model incorporates frame-level and utterance-level attention mechanisms to leverage the relationships among multiple utterances. Additionally, we enhance optimization through data augmentation techniques, including conventional noise augmentation with MUSAN and RIRs datasets, and a novel speaker embedding-level mixup strategy.
Chang Zeng
,
Xiaoxiao Miao
,
Xin Wang
,
Erica Cooper
,
Junichi Yamagishi
PDF
Cite
Dataset
Project
DOI
CSL
Improving Generalization Ability of Countermeasures for New Mismatch Scenario by Combining Multiple Advanced Regularization Terms
The ability of countermeasure models to generalize from seen speech synthesis methods to unseen ones has been investigated in the ASVspoof challenge. However, a new mismatch scenario in which fake audio may be generated from real audio with unseen genres has not been studied thoroughly. To this end, we first use five different vocoders to create a new dataset called CN-Spoof based on the CN-Celeb1&2 datasets. Then, we design two auxiliary objectives for regularization via meta-optimization and a genre alignment module, respectively, and combine them with the main anti-spoofing objective using learnable weights for multiple loss terms.
Chang Zeng
,
Xin Wang
,
Xiaoxiao Miao
,
Erica Cooper
,
Junichi Yamagishi
PDF
Cite
Code
Project
DOI
Interspeech2023
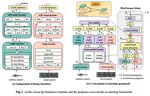
Cross-Modal Audio-Visual Co-Learning for Text-Independent Speaker Verification
Visual speech (i.e., lip motion) is highly related to auditory speech due to the co-occurrence and synchronization in speech production. This paper investigates this correlation and proposes a cross-modal speech co-learning paradigm. The primary motivation of our cross-modal co-learning method is modeling one modality aided by exploiting knowledge from another modality. Specifically, two cross-modal boosters are introduced based on an audio-visual pseudo-siamese structure to learn the modality-transformed correlation. Inside each booster, a max-feature-map embedded Transformer variant is proposed for modality alignment and enhanced feature generation. The network is co-learned both from scratch and with pretrained models. Experimental results on the test scenarios demonstrate that our proposed method achieves around 60% and 20% average relative performance improvement over baseline unimodal and fusion systems, respectively.
Meng Liu
,
Kong Aik Lee
,
Longbiao Wang
,
Hanyi Zhang
,
Chang Zeng
,
Jianwu Dang
PDF
Cite
Project
DOI
ICASSP
Deep Spectro-temporal Artifacts for Detecting Synthesized Speech
Audio Deep Synthesis Detection, Spectro-temporal, Domain Adaptation, Self-Supervised Learning, Frame transition, Greedy Fusion.
Xiaohui Liu
,
Meng Liu
,
Lin Zhang
,
Linjuan Zhang
,
Chang Zeng
,
Kai Li
,
Nan Li
,
Kong Aik Lee
,
Longbiao Wang
,
Jianwu Dang
PDF
Cite
Project
DOI
ACMMM Link
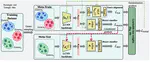
Data Augmentation Using McAdams-Coefficient-Based Speaker Anonymization for Fake Audio Detection
We propose a fake audio detection (FAD) system using speaker anonymization (SA) to enhance the distinction between synthetic and natural speech. The key strategy is to remove speaker-specific information from acoustic speech before it’s processed by a deep neural network (DNN)-based FAD system. We employed the McAdams-coefficient-based SA algorithm to ensure that speaker information doesn’t influence DNN learning. Our system, based on a light convolutional neural network bidirectional long short-term memory (LCNN-BLSTM), was tested on the Audio Deep Synthesis Detection Challenge (ADD2022) datasets. Results indicate a 17.66% performance improvement in the first track of ADD2022 by eliminating speaker information from the acoustic speech.
Kai Li
,
Sheng Li
,
Xugang Lu
,
Masato Akagi
,
Meng Liu
,
Lin Zhang
,
Chang Zeng
,
Longbiao Wang
,
Jianwu Dang
,
Masashi Unoki
PDF
Cite
Project
DOI
INTERSPEECH Link
Spoofing-Aware Attention based ASV Back-end with Multiple Enrollment Utterances and a Sampling Strategy for the SASV Challenge 2022
Current state-of-the-art automatic speaker verification (ASV) systems are vulnerable to presentation attacks, and several countermeasures (CMs), which distinguish bona fide trials from spoofing ones, have been explored to protect ASV. However, ASV systems and CMs are generally developed and optimized independently without considering their inter-relationship. In this paper, we propose a new spoofing-aware ASV back-end module that efficiently computes a combined ASV score based on speaker similarity and CM score.
Chang Zeng
,
Lin Zhang
,
Meng Liu
,
Junichi Yamagishi
PDF
Cite
Project
Video
DOI
INTERSPEECH Link
Attention Back-end for Automatic Speaker Verification with Multiple Enrollment Utterances
Probabilistic linear discriminant analysis (PLDA) or cosine similarity has been widely used in traditional speaker verification systems as a back-end technique to measure pairwise similarities. To make better use of multiple enrollment utterances, we propose a novel attention back-end model that is applied to the utterance-level features. Specifically, we use scaled-dot self-attention and feed-forward self-attention networks as architectures that learn the intra-relationships of enrollment utterances.
Chang Zeng
,
Xin Wang
,
Erica Cooper
,
Xiaoxiao Miao
,
Junichi Yamagishi
PDF
Cite
Code
Dataset
Project
Video
DOI
ICASSP
DeepLip: A Benchmark for Deep Learning-Based Audio-Visual Lip Biometrics
speaker recognition, audio-visual, lip biometrics, deep learning, visual speech.
Meng Liu
,
Longbiao Wang
,
Kong Aik Lee
,
Hanyi Zhang
,
Chang Zeng
,
Jianwu Dang
PDF
Cite
Project
DOI
ASRU Link
Cite
×